
Ethnicity pay gap reporting in the UK
As we have reported previously, the government has been largely silent on ethnicity pay gap reporting and the Commission on Race and Ethnic Disparities recommended against mandatory reporting in its report last March. Business groups have in contrast tended to come down on the other side of the argument. In July, a rare alliance of the Confederation of British Industry, the Trades Union Congress, and the Equality and Human Rights Commission wrote a joint letter to Cabinet Office minister Michael Gove, calling for mandatory ethnicity pay gap reporting be introduced to help tackle racial inequalities at work.
With many different organisations urging the government for clarity on ethnicity pay gap reporting, it will surely be required to respond meaningfully at some point. But when and how it will do so is anyone’s guess. In the meantime, employers wanting to calculate their ethnicity pay gap must simply do the best they can.
Problems arising from incomplete data
Probably the most difficult issue is that, in the absence of any legal obligation on employers to report, employees cannot be compelled to hand over their ethnicity data. Because race can be a sensitive subject, and because ethnicity data is a special category of personal data, employers invariably find they are having to analyse an incomplete dataset.
An employer could have data for 80-90% of its workforce, which might sound like a good completion rate. Yet it still means that there are potentially thousands of possible ethnicity pay gaps, only one of which will be the true one.
For example, if there is one person who has not provided their data, it means that there are two possible sets of gaps, depending upon whether the person is white or an ethnic minority. They will be counted in either one group of the other.
If two people have not provided their data, there are four possible sets of gaps. Both employee 1 and employee 2 could be white, both could be an ethnic minority, employee 1 could be white and the other not, or employee 2 could be white and the other not.
For each extra person who has not provided their data, the number of possible gaps doubles. This means that ten missing people results in 1,024 possible gaps, while a shortfall of 20 people leads to over a million potential gaps. For an employer with 300 staff and a 90% completion rate for their ethnicity data, the 30 missing people will mean there are over a billion conceivable ethnicity pay gaps!
Options for ethnicity pay gap reporting with a partial dataset
There are two possible approaches that an employer might take in this scenario. Most employers will take the simplest approach of simply disregarding the “no data” individuals, and then comparing their ethnic minority data against their data for white staff.
The pitfall of this approach, however, is that the figure reported is certain to be wrong because it fails to take account of all the information from all staff. There might be high-earning ethnic minority staff that should be reducing the gap, or high-earning white staff that should be increasing it.
An alternative approach is to calculate all possible gaps, understand the spread of possible results, and then determine where it is most likely that the true number sits. The case study below is fictional but based on actual (rather than simulated) data and shows how this can be a useful method in practice.
Case study: understanding and explaining the uncertainty of incomplete data
ParaSol is a (fictitious) small tech company with 350 employees, all but 11 of whom have provided their ethnicity data. It has tried and tried to persuade the remaining staff, but this is the best it can do.
The company starts by calculating a mean ethnicity pay gap using the data that it has: all ethnic minority individuals compared to all white individuals. This calculation shows a 23.0% mean pay gap.
ParaSol wants, however, to try to deal with some of the uncertainty created by the 11 missing people. It concludes that there are 2,048 different possible combinations of ethnicity for these 11 staff (since 2x2x2x2x2x2x2x2x2x2x2 = 211 = 2,048).
Having calculated all 2,048 different possible combinations of ethnicity for the missing staff, ParaSol finds there is a big range. The highest possible mean pay gap is 29.4% and the lowest is 4.5%, but most tend to be somewhere in the middle. ParaSol plots all points on a histogram:
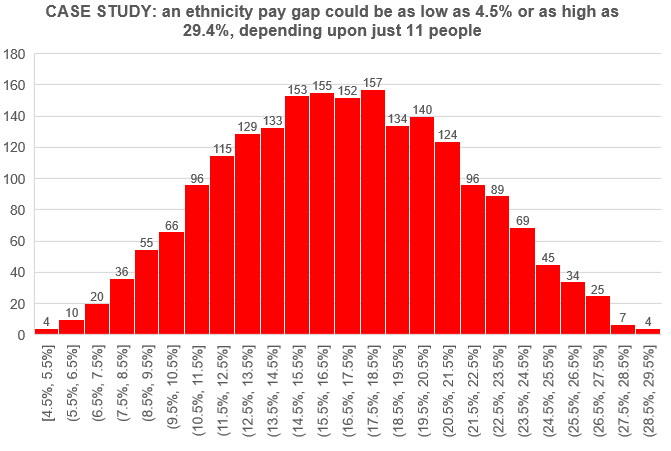
ParaSol therefore decides to write the following in its ethnicity pay gap report:
“We do not have ethnicity data for all of our staff and we cannot compel them to provide it, which makes calculating an accurate ethnicity pay gap difficult. A calculation based on the data that we do have results in a 23.0% gap. However, we ran simulations of the missing data and found that 94% of these simulations showed a gap below this figure. This leads us to believe that our true gap is most likely to be around 16.5%.”
Conclusion – get as complete a dataset as possible
Calculating a million or more ethnicity pay gaps is beyond even the powerful abilities of a trusty spreadsheet (which are often underappreciated), yet this is something that is more possible by using other free tools. Nonetheless, datasets that are missing details of 50 or more people – where there are a quadrillion different possible gaps – become more difficult to analyse and require different approaches altogether.
The fact that each additional individual who has not provided ethnicity data leads to an exponential increase in the number of possible ethnicity pay gaps means it is crucial to obtain as complete a dataset as possible. While employers should be careful to ensure employees do not feel pressured into handing over their personal data, they should not shy away from being upfront about asking them to provide it if they are to reduce the uncertainty caused by missing data. Targeted “nudge” emails explaining why the data is useful can, for example, be an effective means of increasing your dataset.
Find out more about our ethnicity pay gap reporting solution.